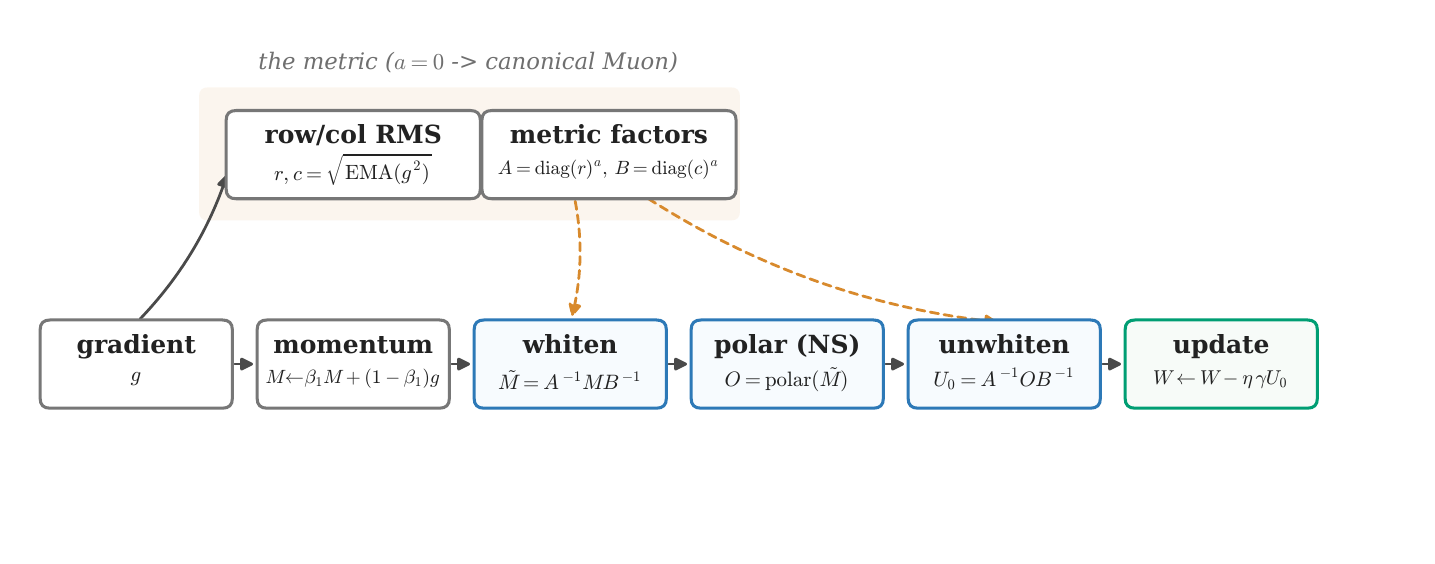
Muon accelerates neural network training by replacing each weight matrix update with the
nearest orthogonal matrix to its momentum, computed through a Newton–Schulz polar
iteration. This orthogonalization is performed in the standard Euclidean (Frobenius) geometry,
which treats every row and column of the gradient as equally scaled. We show that this metric is
suboptimal and that a single, cheap correction recovers a consistent gain.
Weighted-Muon computes the polar factor in a metric defined by the
exponentially averaged row and column RMS of the gradient: it whitens the momentum by diagonal
row and column factors, orthogonalizes the whitened matrix, and unwhitens the result. This is the
Muon analogue of Adam's per-coordinate rescaling, applied at the granularity of matrix rows and
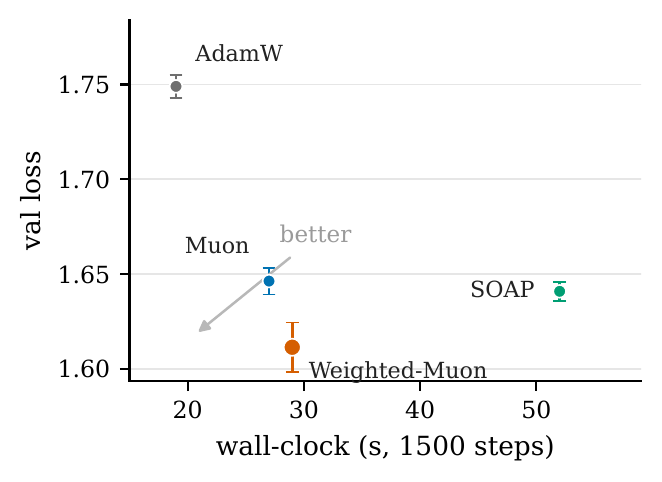
columns. On a from-scratch character-level nanoGPT it reaches validation loss
1.611 ± 0.013 over three seeds, beating Muon (1.646) and SOAP (1.641)
with non-overlapping distributions, at Muon's wall-clock and roughly 1.8× faster than SOAP.
The gain transfers to a real pretrained model (SmolLM2-135M fine-tune) and a graft ablation
confirms it is carried entirely by the update direction the metric induces, not its
magnitude. We also map the boundary: on a vision MLP dominated by correlated input pixels (MNIST),
Weighted-Muon improves on Muon but is surpassed by input-aware and curvature-aware methods,
because it uses no information about the input covariance.
−2.1%
val loss vs Muon on nanoGPT, non-overlapping over 3 seeds
1.8×
faster than SOAP at lower loss (Muon wall-clock)
3 / 3
settings where it beats Muon: nanoGPT, SmolLM2-135M, MNIST
01The idea in one line
Muon orthogonalizes in the wrong geometry. Normalize the polar input by the
running row and column gradient RMS, once per side, and undo it after.
U = A−1 · polar(A−1 M B−1) · B−1 · γ,
A = diag(r)a, B = diag(c)a
Here M is the gradient momentum, r, c are the
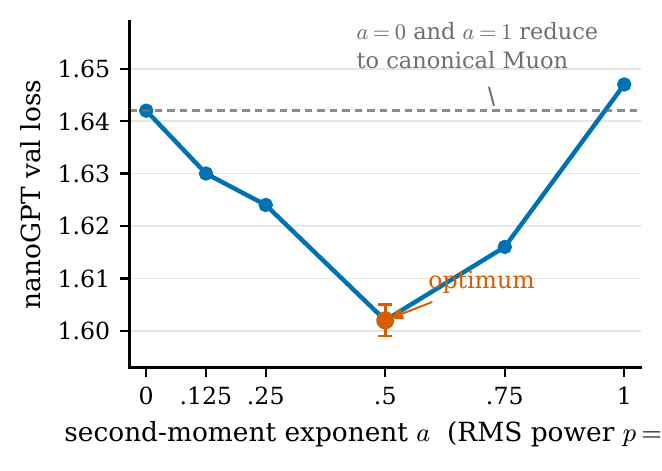
running per-row and per-column gradient RMS, and a = 0.5 normalizes by the
RMS exactly once per side. Setting a = 0 recovers canonical Muon exactly.
The whole change is two vectors of running statistics and two diagonal rescalings per matrix, so the
per-step cost is indistinguishable from Muon.
Figure 1. One Weighted-Muon step. The momentum is whitened by the
diagonal row/column metric built from the running gradient RMS, orthogonalized by a
Newton–Schulz polar iteration, then unwhitened and rescaled to Muon's spectral magnitude.
The shaded path is the metric; setting its power to zero recovers canonical Muon.
02Contributions
A one-line modification of Muon that performs the polar step in a gradient row/column RMS metric, with the correct exponent identified (p = 1, normalize once per side).
On a from-scratch nanoGPT, it beats Muon and SOAP with non-overlapping three-seed distributions, at Muon's wall-clock and ~1.8× faster than SOAP.
An exponent sweep and a magnitude-graft ablation showing the gain is governed entirely by the update direction, not its magnitude.
Validation on a real pretrained model, SmolLM2-135M, where it again beats Muon over two seeds, non-overlapping.
An honest boundary: on a vision MLP dominated by input covariance (MNIST), it rescues Muon but loses to input- and curvature-aware methods.
03Results
From-scratch transformer (nanoGPT)
3 layers, width 128, tinyshakespeare, 1500 steps, batch 32, three seeds. Lower val loss is better.
Optimizer
Val loss
Wall-clock (s)
vs Muon
AdamW
1.7490 ± 0.006
19
+6.2%
Muon
1.6463 ± 0.007
27
0.0%
SOAP
1.6409 ± 0.005
52
−0.3%
Weighted-Muon
1.6114 ± 0.013
29
−2.1%
Figure 2. Loss vs wall-clock. SOAP matches Muon's loss only at ~2× the cost; Weighted-Muon improves on both at Muon's cost.Figure 3. Validation loss vs the exponent. U-shaped with a clear optimum at a = 0.5 (p = 1); both endpoints revert to Muon.
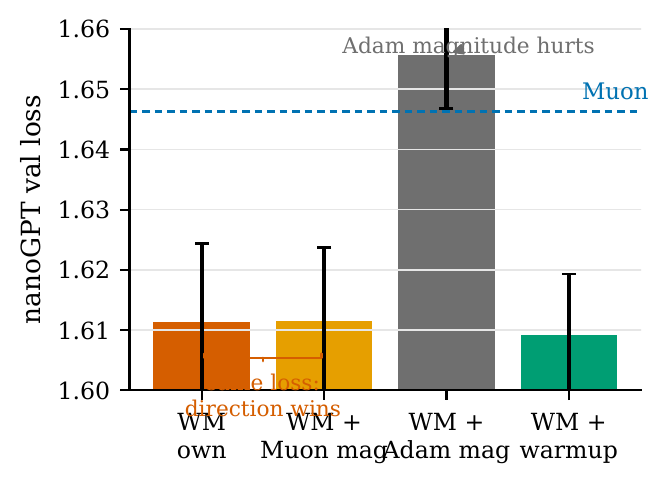
The gain is direction, not magnitude
Grafting Muon's magnitude onto the Weighted-Muon direction leaves the loss unchanged; grafting Adam's magnitude hurts.
Variant
Val loss
WM (own magnitude)
1.6114 ± 0.013
WM + graft Muon mag
1.6117 ± 0.012
WM + graft Adam mag
1.6558 ± 0.009
WM + exponent warmup
1.6093 ± 0.010
Muon (reference)
1.6463 ± 0.007
Figure 4. The Weighted-Muon direction is invariant to whether it carries its own or Muon's magnitude, and degrades only with Adam's magnitude.
Pretrained model fine-tune (SmolLM2-135M)
Full fine-tune on tinyshakespeare, 150 steps, two seeds, Apple MPS. Pretrained baseline 3.247.
Weighted-Muon 3.111 ± 0.009 vs Muon 3.130 ± 0.006,
winning both seeds with non-overlapping distributions. The relative gain is smaller than from
scratch, consistent with adaptive spectral conditioning compounding over more steps.
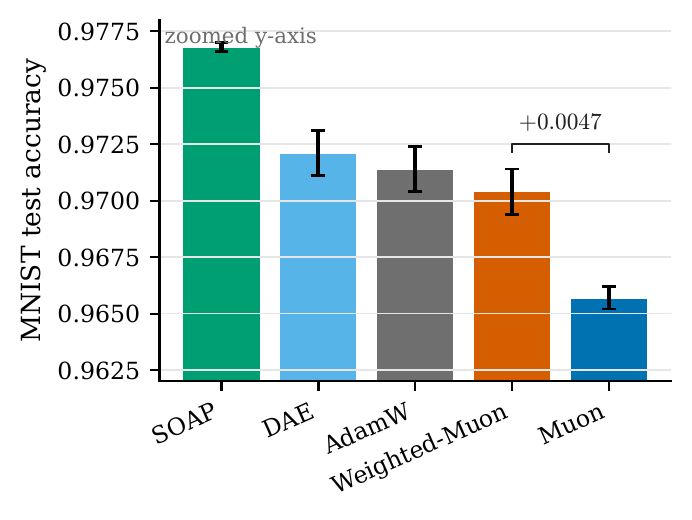
Boundary: input-correlated MLP (MNIST)
784-256-256-10 MLP, 3000 steps, three seeds. Higher test accuracy is better.
Optimizer
Test acc
SOAP
0.9768 ± 0.0002
DAE (input-whitened)
0.9721 ± 0.0010
AdamW
0.9714 ± 0.0010
Weighted-Muon
0.9704 ± 0.0010
Muon
0.9657 ± 0.0005
Figure 5. Weighted-Muon rescues Muon (bracket) but is surpassed by methods that condition on the correlated pixel inputs it never observes.
04Why transformers and not vision MLPs
Weighted-Muon corrects Muon's gradient-side metric and uses no information about the
input covariance. Transformer hidden activations are layer-normalized, so the dominant remaining
difficulty is matrix spectral geometry, which is exactly what the metric addresses. A vision MLP on
raw pixels is dominated instead by correlated inputs, which input-whitening and curvature methods
(SOAP) capture and Weighted-Muon by construction cannot. The honest scope: Weighted-Muon is the best
Muon-family optimizer and the best optimizer we tested on transformers, scratch and fine-tune, while
on raw-correlated-input MLPs input-aware methods remain better.
05Reproduce & cite
The optimizer is about forty lines. Each result is driven by a single script with fixed seeds and
a shared harness (one model init per seed, identical data order, batch size, and step budget across
optimizers).